
Anna Rychlik, Re-Frame & Grow

Szkolenie zaspokaja potrzeby rozwojowe w obszarze Consumer/Shopper/ Market Insight, niezależnie od wielkości wydawanych budżetów i dostępności posiadanych źródeł danych, jeśli w Twojej firmie:
- panuje opinia, że dane rynkowe i konsumenckie są przetwarzane na podstawowym poziomie, że ,,można z tego wyciągnąć więcej’’
- osoby odpowiedzialne za analitykę i badania rynkowe dostarczają do swoich klientów wewnętrznych i zewnętrznych zestawienia danych i przeładowane prezentacje i raporty, a klient samodzielnie poszukuje insightu i wniosków do decyzji biznesowych
- obserwujesz, że procesy biznesowe niedostatecznie wykorzystują dane i badania konsumenckie, uwzględniając kontekst rynkowy na podstawowym poziomie i / lub nieefektywnie go przetwarzając
- odpowiedzialność za czytanie rynku i interpretację danych i badań jest rozproszona w organizacji, rozumienie rynku i konsumenta podlega różnym – czasem sprzecznym lub rozbieżnym - interpretacjom, a formowane wnioski są niespójne
- obecnie wytwarzane w organizacji raporty zarządcze lub analizy rynku nie wspierają realizowanej strategii i jej monitoringu.
Szczegółowy zakres szkolenia:
- Szkolenie jest zaplanowane w taki sposób, by zainicjować i / lub wzmocnić rozwój kluczowych umiejętności w zakresie analityki rynkowej:
- ,,From brief to business recommendation’’ – formułowanie briefu analizy / badania, tłumaczenie briefu na efektywne podejście i plan analizy / badania, logika wnioskowania
- ,,Connect the dots’’ – celowe dobieranie źródeł i łączenie informacji, radzenie sobie z niespójnościami i (nie)wiarygodnością danych, rozumienie faktów
- ,,From data to insight’’ – różnica dane vs insight, transformacja danych w kierunku insight,
- ,,Storytelling’’ – jak łączyć informacje w historię dla biznesu, logika i struktura raportu/prezentacji, język, wykorzystanie danych vs narracja, style komunikacji w narracji dla różnych grup odbiorców
- ,,Management reporting’’ – projektowanie efektywnych raportów zarządczych na bazie ciągłych danych rynkowych wspierających strategię.
- Przykłady wykorzystania w/w w biznesie
Do kogo kierowane jest szkolenie:
Rekomendowani uczestnicy szkolenia to nowi i średniozaawansowani: badacze i analitycy rynku i sprzedaży po stronie producenta, detalisty, agencji; Consumer & Market Insight Managerowie, Category Managerowie, Junior/Brand Managerowie. Specjaliści i kierownicy, którzy odpowiadają za: bieżący monitoring ciągłych danych rynkowych i raportowanie zarządcze na bazie danych retail audit (w tym Nielsen i GFK HH Panel), projektowanie i dostarczanie wszelkich badań konsumenckich, szoperowych, rynku, analitykę rynkową, rozwój portfolio i komunikacji mediowej marek, rozwój i monitoring strategii cenowej, projektowanie i post analizy aktywacji marketingowych i promocji konsumenckich, budowanie ekspertyzy kategorialnej i category management dla detalistów.Korzyści dla uczestników:
Szkolenie zainicjuje u początkujących, a rozwinie u bardziej zaawansowanych uczestników:- Wnikliwe rozumienie danych rynkowych i konsumenckich, efektywne łączenie danych z wielu źródeł dla wsparcia kluczowych procesów biznesowych, umiejętność interpretacji i wyciągania wniosków, perswazyjność przekazu do różnych grup odbiorców
- Rozwój biznesowego sposobu myślenia u badaczy i analityków i adekwatne odpowiadanie na potrzeby top i senior management
- Zwiększenie bezpośredniego wpływu badaczy i analityków na biznes i wyjście ,,z zaplecza na front’’ do roli partnera biznesowego dla top i senior managementu
Kluczowe pojęcia i zagadnienia:
,,From brief to business recommendation’’ / planowanie analizy / logika wnioskowania / kontekst biznesowy / pytania biznesowe / pytania badawcze / klient wewnętrzny i zewnętrzny/ procesy i decyzje biznesowe,,Connect the dots’’ / rozumienie faktów i danych / dobór źródeł danych / łączenie informacji / detal a duży obrazek / niespójności i jakość danych
,,From data to insight’’ / dane vs insight / transformacja danych w insight
,,Storytelling’’ / historia dla klienta / struktura raportu / logika prezentacji / język narracji / wykorzystanie danych w narracji /style komunikacji vs grupy odbiorców
,,Management reporting’’ / projektowanie raportów zarządczych / tracking rynku a strategia / czytanie rynku
Forma szkolenia:
Szkolenie łączy formę warsztatu ze studium przypadków i mini wykładu jako wprowadzenie do każdego bloku tematycznego. Szkolenie zorganizowane w 5 modułów wg kompetencji analitycznych (patrz: Szczegółowy zakres szkolenia).Plan godzinowy:
1 dzień:
9.00-11.00 - I moduł
11.00-13.00 - przerwa
13.00-14.30 - II moduł
14.30-14.45 - przerwa
14.45-16.15 - III moduł
2 dzień:
9.00-10.30 - IV moduł
10.30-10.45 - przerwa
10.45-12.15 - V moduł
Stopień zaawansowania:
Szkolenie zaspokaja potrzeby rozwojowe w obszarze analityki rynkowej u osób:- w początkowej fazie kariery zawodowej, tj ze stażem poniżej 1 roku w obszarze marketingu, badań, analityki i insightu rynkowego (CMI), zarządzania kategorią .
- dłużej pracujących w w/w rolach, tj. ze stażem powyżej 1 roku, które mierzą się ze zmieniającymi się oczekiwaniami wobec zajmowanej funkcji ze strony biznesu.



Rychlik
Re-Frame & Grow
czas trwania: 8 godzin zegarowych w przeciągu 2 dni
miejsce: ONLINE
w cenie: udział w szkoleniu, materiały w wersji elektronicznej, certyfikat elektroniczny, 30 minutowe konsutacje indywidulane (zoom/telefon/e-mail)
Chcesz wiedzieć więcej?
więcej informacji udzieli Ci koordynator szkoleń
Anna Chodkiewicz
– poziom średniozaawansowany
Marek Młodożeniec, Sotrender
Szczegółowy zakres szkolenia:
Część 1: Instrumentarium Data Scientist- Tworzenie własnych funkcji
- składnia funkcji
- argumenty funkcji: wymagane i domyślne wartości
- zwracanie wartości w sposób jawny i ukryty
- obsługa błędów
- wczytywanie podręcznego zestawu funkcji z zewnętrznych skryptów
- Wykonywanie zadań w pętlach
- składnia pętli for i while
- funkcje z rodziny apply()
- Wczytywanie danych ze źródeł zewnętrznych
- wczytywanie danych wprost z arkuszy Excel
- zapis i odczyt danych w formacie RDS
- przykłady wczytywania danych ze źródeł zewnętrznych: Google Drive, bazy SQL, API zewnętrznych aplikacji, web scraping
- Łączenie baz danych wierszami (dołączanie przypadków)
- Przekształcanie struktury danych z formatu długiego w format szeroki i na odwrót
- Przygotowanie danych do dalszej analizy z wykorzystaniem operatora potoku (%>%)
- sortowanie zbioru
- usuwanie i podmiana braków danych
- filtrowanie obserwacji
- selekcja zmiennych i modyfikacja ich nazw
- tworzenie zmiennych będących funkcjami zmiennych istniejących
- grupowanie i wyliczanie parametrów w podgrupach
- łączenie baz danych kolumnami (dołączanie zmiennych)
- Analiza czynnikowa i analiza głównych składowych
- idea i zastosowania analizy czynnikowej
- dobór parametrów analizy: metoda rotacji
- sposób interpretacji wyników
- ocena jakości rozwiązania i sposoby jego poprawy
- tworzenie map percepcyjnych z wykorzystaniem analizy czynnikowej
- Modele regresyjne
- model regresji jako narzędzie opisu i przewidywania
- regresja liniowa: interpretacja współczynników równania i wartości R2
- szacowanie siły wpływu: indeks Pratta
- poprawa dopasowania modelu:
- minimalizacja wzajemnego skorelowania predyktorów
- nieliniowe przekształcenia zmiennych: rule of the bulge
- eliminacja przypadków odstających
- metody poprawy rozwiązania: selekcja predyktorów
- dodawanie interakcji międzyzmiennowych do modelu
- regresja nieliniowa: wielomianowa i logistyczna
- Analiza skupień (clustering)
- zastosowania analizy skupień: znaczenie biznesowe segmentacji rynku
- przygotowanie danych do analizy skupień: standaryzacja i ortogonalizacja zmiennych, eliminacja przypadków odstających
- clustering hierarchiczny i clustering k-średnich: wybór parametrów analizy
- interpretacja i wizualizacja wyników analizy skupień
- kryteria wyboru optymalnego rozwiązania
- Analiza korespondencji
- przygotowanie danych wejściowych do analizy
- interpretacja wyników
- generowanie mapy korespondencji i dostosowanie jej wyglądu
- wykorzystanie analizy korespondencji do wizualizacji wizerunku marki
Do kogo kierowane jest szkolenie:
Kurs średniozaawansowany został stworzony dla osób, które posiadają już podstawowe umiejętności analizy danych w języku R (np. wczytywanie pliku CSV, opis parametryczny jednej zmiennej, generowanie tabel itp.). Na szkolenie średniozaawansowane zapraszamy więc osoby, które znają już trochę język R, ale chciałyby nabrać w posługiwaniu się nim większej biegłości, lub opanować techniki analityczne stosowane w branży badań rynku. W podążaniu za programem kursu pomocna będzie podstawowa wiedza z zakresu statystyki oraz doświadczenie w stosowaniu omawianych metod, np. w pakiecie SPSS.Korzyści dla uczestników:
Po ukończeniu tego szkolenia uczestnik będzie potrafił:- Definiować własne funkcje statystyczne
- Uruchamiać skrypty bez otwierania ich w edytorze (wstęp do programowania modularnego)
- Wykonywać operacje w pętlach
- Wczytywać dane z wybranej zakładki w arkuszu Excel i z formatu RDS
- Łączyć bazy danych wierszami (dodawanie przypadków) i kolumnami (dodawanie zmiennych)
- Zmieniać format danych z formatu baz relacyjnych („długiego”) na częściej stosowany w badaniach format „szeroki”
- Posługiwać się funkcjami pakietów dplyr i tidyr do przetwarzania zbiorów danych, w celu przygotowania danych do dalszej analizy
- Wykonywać analizę czynnikową i interpretować jej wyniki
- Tworzyć mapy percepcyjne z wykorzystaniem czynników
- Przeprowadzać analizę regresji, interpretować jej wyniki i optymalizować dopasowanie modelu
- Szacować procentowy udział siły wpływu każdego z predyktorów na zmienną zależną
- Interpretować wyniki regresji liniowej z interakcją i bez, wielomianowej oraz logistycznej
- Przeprowadzać analizę skupień metodami hierarchicznymi i k-średnich
- Wybierać podział zbioru najbardziej obiecujący pod kątem segmentacji rynku
- Przeprowadzać analizę korespondencji
- Generować i interpretować mapę korespondencji zawierającą marki i cechy wizerunkowe
Kluczowe pojęcia i zagadnienia:
Pojęcia z zakresu programowania: wymagane i opcjonalne argumenty funkcji, domyślna wartość argumentu, wrapper, funkcja przeciążona, obsługa błędów, programowanie modularne, pętla, inkrementacja, warunek stopu, API, format JSON, długi i szeroki format danych, potok (pipeline)Pojęcia statystyczne: czynnik, standaryzacja, rotacja, wykres osypiska, ładunki czynnikowe, predykcja, zależność liniowa i nieliniowa, zmienna zależna i predyktory, moc predykcyjna modelu, współczynniki standaryzowane Beta, współczynnik Pratta, skorelowanie wzajemne, przypadki odstające, przekształcenie nieliniowe, logarytm, wielomian, logit, ortogonalność, segmentacja, skupienie (cluster), metryka, odległość Euklidesowa, metoda aglomeracji, profil wierszowy i kolumnowy, rozkład wg. wartości osobliwych macierzy (singular value decomposition, SVD), masa i moment punktu
Forma szkolenia:
Szkolenie będzie miało formę warsztatową. Zdecydowaną większość czasu spędzimy, pisząc i testując kod na własnych komputerach. Moduły tematyczne składające się z teorii i przykładów będą przedzielane ćwiczeniami indywidualnymi, służącymi utrwaleniu materiału.Stopień zaawansowania:
Kurs średniozaawansowany jest kontynuacją i rozwinięciem szkolenia „R dla badaczy – poziom podstawowy”, toteż opanowanie podstawowych umiejętności analizy danych w R (niekoniecznie w ramach szkolenia podstawowego) z powodzeniem wystarczy do podążania za programem kursu średniozaawansowanego. Podstawowa wiedza na temat omawianych metod analitycznych (analiza czynnikowa, analiza regresji, analiza skupień i analiza korespondencji) będzie pomocna, ale zagadnienia te w razie potrzeby zostaną objaśnione.

Młodożeniec
Sotrender
czas trwania: 16 godzin szkoleniowych w godz. 9.00-16.30
miejsce: PTBRiO, Szarotki 11, Warszawa
Uwaga! Ze względu na panującą pandemię organizator szkolenia zastrzega sobie prawo zmiany miejsca, terminu oraz formuły (stacjonarna/ online) szkolenia. O wszelkich ewentualnych zmianach uczestnicy szkolenia będą informowani na bieżąco.
w cenie: udział w szkoleniu, materiały, certyfikat, przerwy kawowe, lunch
Chcesz wiedzieć więcej?
więcej informacji udzieli Ci koordynator szkoleń
Anna Chodkiewicz

Agnieszka Warzybok (ABM/decode)
Dołącz do szkolenia, poznaj odpowiedzi na powyższe pytania oraz obejrzyj zapis VOD największego projektu trendwatchingowego w Polsce!

Szczegółowy zakres szkolenia:
Do kogo kierowane jest szkolenie:
Badaczy rynku, osób zawodowo zajmujących się komunikacją (marketing, PR), strategów.Korzyści dla uczestników:
- Inspiracja do samodzielnego trendwatchingu
- Rozumienie różnych definicji trendów konsumenckich
- Umiejętność zrozumienia i oceny różnych analiz trendów
- Umiejętność samodzielnego poszukiwania trendów
- Umiejętność krytycznego podejścia do zjawisk typu fad, moda
Kluczowe pojęcia i zagadnienia:
Trendy konsumenckie, trendy kulturowe, trendy rynkowe, trendy demograficzne. Strategie rynkowe oparte na trendach. Badania trendów, prognozowanie trendówForma szkolenia:
Online (Clickmeeting, Miro), w formie 2 półdniowych sesji. Szkolenie łączy teorię z praktyką. Przy każdym omawianym pojęciu uczestnicy sięgają do własnych doświadczeń, aby lepiej zrozumieć dane zjawisko.Stopień zaawansowania:
Szkolenie wymaga wiedzy o jakościowych i ilościowych metodach badawczych

Warzybok
ABM/decode
czas trwania: 2 dni w godz. 9.00-13.00
miejsce: ONLINE (Clickmeeting, Miro)
w cenie: udział w szkoleniu, materiały elektroniczne, certyfikat elektroniczny, miesięczny dostęp do VOD Trend Week

- warsztaty improwizacji stosowanej
Bart Jurkowski, I’MPRO IMPRO
Rozwiń swoje kompetencje miękkie, inteligencję emocjonalną oraz umiejętność skutecznego działania bez schematu podczas interaktywnych warsztatów improwizacji stosowanej z I’MPRO IMPRO.
Improwizacja stosowana to metoda warsztatowa łącząca ćwiczenia scenicznej improwizacji teatralnej wraz z ich praktycznym zastosowaniem w profesjonalnym świecie. Dzięki takim zajęciom w przyjemny sposób można rozwijać umiejętność skutecznego działania bez schematu, swoją inteligencję emocjonalną oraz takie kompetencje miękkie jak współpraca, kreatywność oraz pewność siebie.
DLACZEGO WARTO?⭐️
Zajęcia z improwizacji stosowanej znajdują się w programach takich prestiżowych uniwersytetów jak Massachusetts Institute of Technology (MIT), Stanford czy Uniwersytet Kalifornijski (UCLA). Improwizacji uczą się także przyszli liderzy na kierunkach MBA, a także pracownicy takich firm jak np. Google, Microsoft czy Pixar. Dlaczego? Ponieważ impro łączy praktyczny rozwój kluczowych kompetencji miękkich (błyskotliwość, uważność, pewność siebie, etc.) z interaktywną, luźną formułą zajęć.
CO BĘDZIEMY ROBIĆ? 👌
Kurs ma formę interaktywnych warsztatów online wypełnionych grami, zabawami oraz zadaniami kreatywnymi. Poprzez te ćwiczenia będziemy wyciągać wnioski na temat naszych nawyków działania, stylów komunikacyjnych oraz emocji. Wszystko to uzupełni kilka teorii psychologicznych oraz materiały dodatkowe przesyłane po każdym warsztacie. Będziemy się rozwijać, ale przede wszystkim dobrze się bawić.
Szczegółowy zakres szkolenia:
Program będzie realizowany podczas 4 interaktywnych spotkań w kameralnej grupie (do 12 osób). Każde spotkanie będzie poświęcone dedykowanym zagadnieniom:- Autoprezentacja, naturalność oraz aktywne słuchanie
- Współpraca, uważność oraz zaufanie
- Kreatywność, innowacyjność i popełnianie błędów
- Adaptacja, elastyczność i działanie bez schematu
Do kogo kierowane jest szkolenie:
- do wszystkich, których praca opiera się na kontaktach z ludźmi (członkami zespołu oraz z klientami)
- do wszystkich, którzy chcą rozwijać swoje kompetencje interpersonalne
- do profesjonalistek i profesjonalistów, którzy chcą rozwijać swoją inteligencję emocjonalną
- do managerek i managerów koordynujących pracę zespołu ludzi
- do ekspertek i ekspertów, którzy lubią się uczyć poprzez doświadczanie i samodzielne wyciąganie wniosków
Korzyści dla uczestników:
Po ukończeniu warsztatów, ich uczestnicy:- poznają swoje nawyki związane z autoprezentacją, współpracą oraz kreatywnością
- rozwiną swoją empatię oraz zrozumienie dla osób, które posiadają inne nawyki
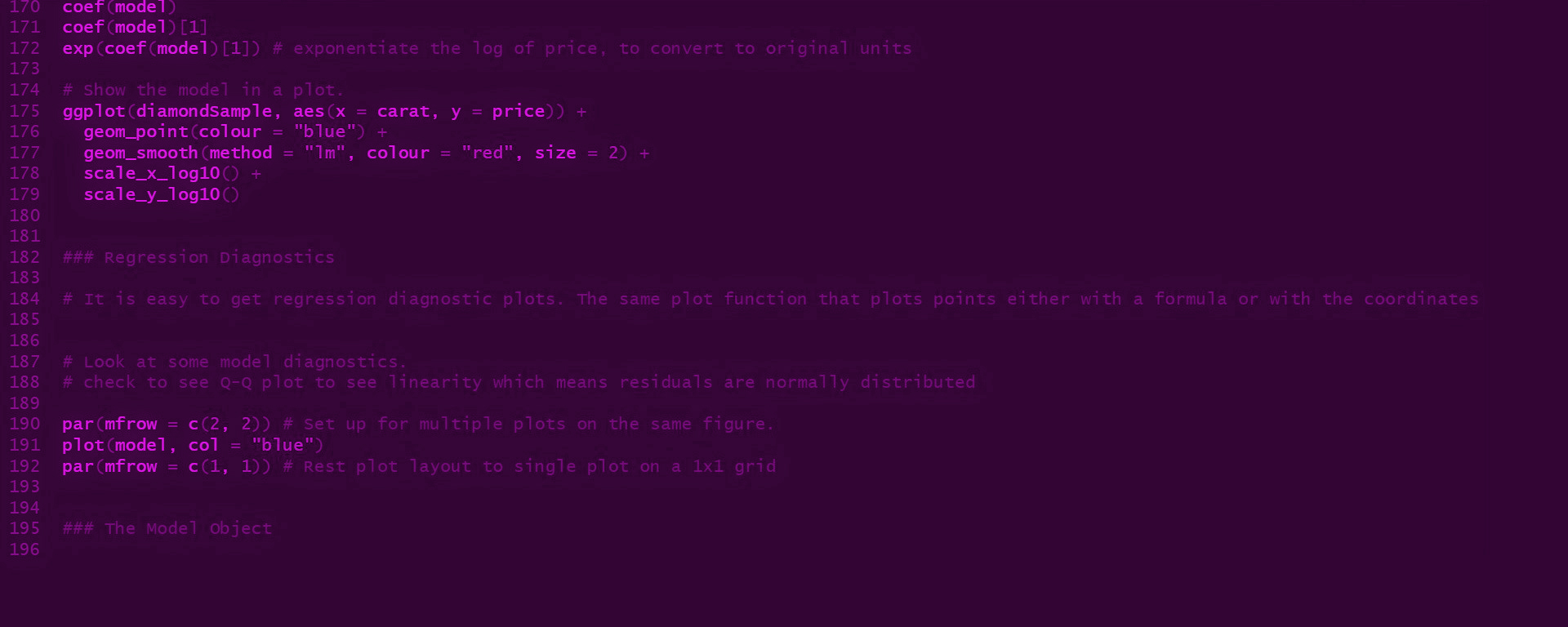
- poznają wartość autentyczności w autoprezentacji oraz w kontaktach z innymi ludźmi
- rozwiną swoją uważność oraz umiejętność aktywnego słuchania
- poznają skuteczne sposoby radzenia sobie z wewnętrznym krytykiem, zwiększając swoją spontaniczność
- poznają czynniki wpływające na zwiększenie współpracy pomiędzy członkami zespołu
- nauczą się nowej techniki zwiększającej ilość i różnorodność pomysłów generowanych przez grupę podczas spotkań kreatywnych/burz mózgów - do wykorzystania w codziennej pracy
- zrozumieją, w jaki sposób mogą lepiej dopasowywać się do rozmówców zwiększając swoją satysfakcję z komunikacji
- poznają sposoby na zwiększenie innowacyjności w zespole
- rozwiną swoją tolerancję na niepewność
- rozwiną swoją umiejętność skutecznego działania bez schematu
Kluczowe pojęcia i zagadnienia:
Improwizacja stosowana, impro, human skills, współpraca, kreatywność, innowacyjność, zespołowość, komunikacja, ocenianie siebie, ocenianie innych, uważność, aktywne słuchanie, zaufanie, reagowanie na błędy swoje i innych, elastyczność, dopasowywanie się, działanie bez schematu.Forma szkolenia:
Warsztaty odbędą się w formule zdalnej z wykorzystaniem platformy Zoom oraz Mural. Zbudujemy przyjazne digitalowe środowisko zdalnej pracy grupowej wykorzystując kamerki, mikrofony oraz przestrzeń fizyczną w naszych domach/biurach. Każdy z 2h warsztatów będzie wypełniony interaktywnymi zadaniami, grami oraz ćwiczeniami impro, które będziemy przeplatać z dyskusjami grupowymi, wyciąganiem wniosków oraz przekładaniem ich na grunt zawodowy. Wszystko to w luźnej i nieformalnej atmosferze dobrej zabawy.Stopień zaawansowania:
Uczestnicy nie muszą posiadać żadnych określonych umiejętności. Jedynym wymaganiem jest posiadanie sprawnej kamerki internetowej, mikrofonu, słuchawek oraz urządzenia z dostępem do internetu.
Opinie poprzednich uczestników warsztatów:
„Miałem przyjemność uczestniczyć w warsztatach impro online. Profesjonalizm i duże zaangażowanie prowadzącego udzieliło się wszystkim uczestnikom zajęć. Dużą zaletą zajęć było to, że wszelkie wnioski z ćwiczeń Bart przekładał na praktykę biznesową. Polecam współpracę z I’MPRO IMPRO.”
Michał Próchnicki,
Head of Paid Social, e-obowie.pl SA
„Miałam okazję dwukrotnie uczestniczyć w warsztatach improwizacji stosowanej prowadzonych przez Barta w Google (offline i online). Muszę powiedzieć, że za każdym razem byłam pod wrażeniem sposobu, w jaki Bart otwiera ludzi podczas tych sesji. Zdecydowanie polecam I’MPRO IMPRO i ten warsztat każdej firmie, która chce stworzyć otwarty i kreatywny zespół, który myśli nieszablonowo!”
Magdalena Bornos-Paciorek,
Industry Manager, Google Polska
„Jeżeli macie jakikolwiek kontakt z ludźmi (zespołem projektowym, klientem, swoim zespołem), polecam ten warsztat z całego serca. Atmosfera jest świetna, prowadzący wie co robi i jest w tym bardzo ludzki. Jest sporo wiedzy pobieranej z prawdziwych doświadczeń. Cała zaleta tego warsztatu jest taka, że czujesz na własnej skórze jak działają przeróżne schematy komunikacji oraz myślenia, a nie czytasz o tym w artykule. Jako projektanta i szefa zespołu, było to dla mnie bardzo rozwijające przeżycie.”
Paweł Hawrylak,
Head of Design, Monterail


Jurkowski
I’MPRO IMPRO
termin:
godz. 9.00-11.00, poniedziałki i czwartki,
18, 21, 25 i 28 stycznia 2021 r.
czas trwania: 8 godzin podzielonych na 4 dwugodzinne sesje
miejsce: ONLINE
Uwaga! Ze względu na panującą pandemię organizator szkolenia zastrzega sobie prawo zmiany miejsca, terminu oraz formuły (stacjonarna/ online) szkolenia. O wszelkich ewentualnych zmianach uczestnicy szkolenia będą informowani na bieżąco.
w cenie: udział w szkoleniu, materiały elektroniczne, certyfikat elektroniczny
Chcesz wiedzieć więcej?
więcej informacji udzieli Ci koordynator szkoleń
Anna Chodkiewicz



